If you're reading this, you probably manage some DynamoDB tables, and your metrics on some of them look like this:
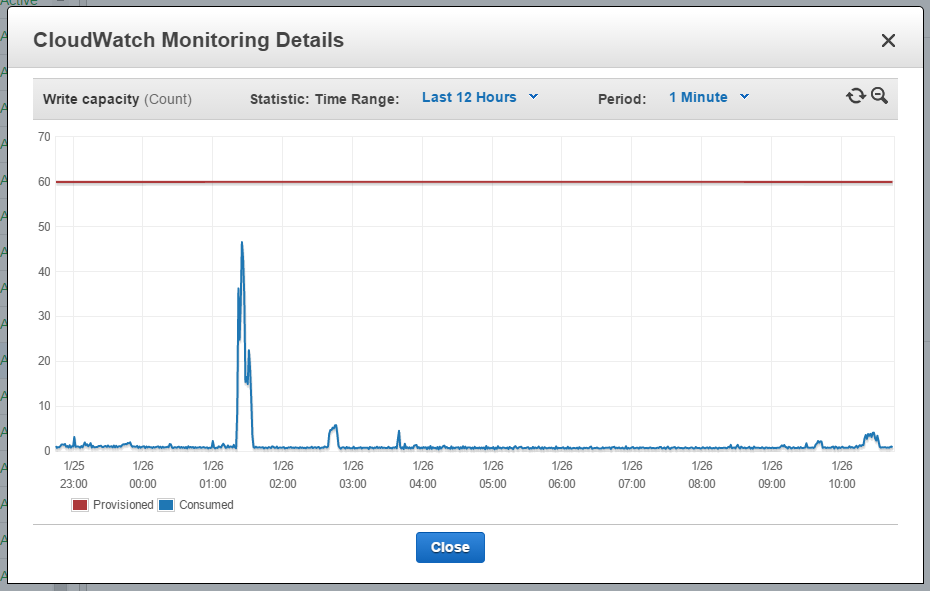
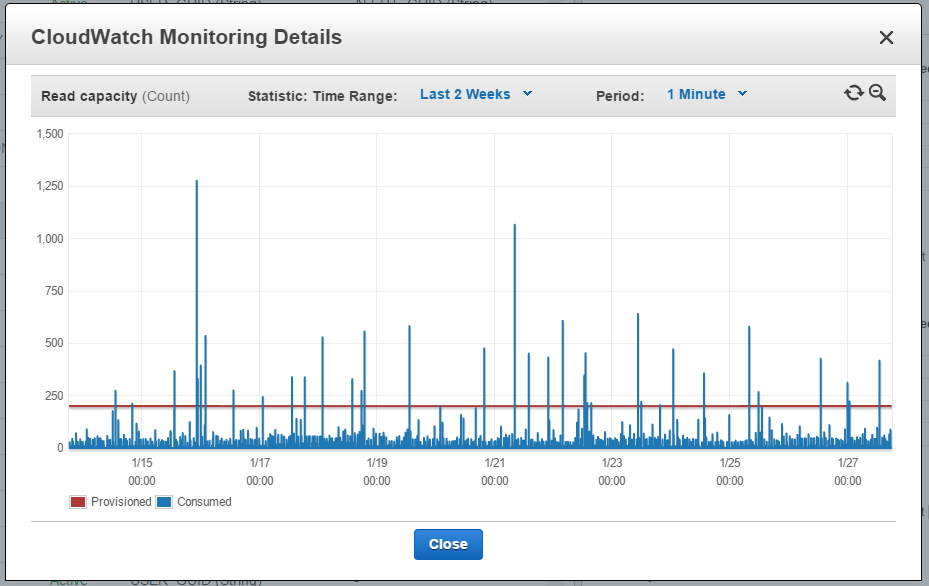
A table provisioned/consumed capacity, with most of provisioned capacity unused (and that means money burning). Note that Burst Capacity feature does not always work for this kind of peaks (image 1), and
there is always a more complex table to manage (image 2).
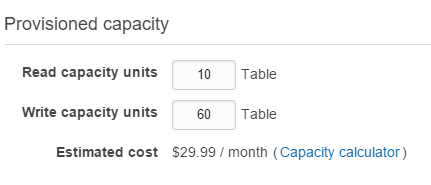
In my scenario - a GPS tracking app called WhereAreYouGPS.com / MapME.net -, I use 16 tables to save mobile device locations. Without implementing any DynamoDB scaling strategy, the cost is up to 16 x $30 = $484 (just for a 'single' table). Assuming most of the time the related tables just need 1/6th of current provisioned capacity, the cost could be near 16 * $6 = $96.
How to go there?
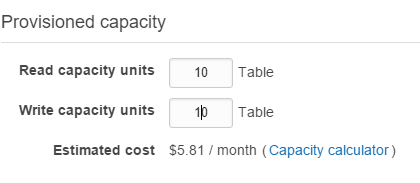
In my scenario - a GPS tracking app called WhereAreYouGPS.com / MapME.net -, I use 16 tables to save mobile device locations. Without implementing any DynamoDB scaling strategy, the cost is up to 16 x $30 = $484 (just for a 'single' table). Assuming most of the time the related tables just need 1/6th of current provisioned capacity, the cost could be near 16 * $6 = $96.
How to go there?
Option 1: use a low value for provisioned capacity + manage exceptions
That means no scale strategy, and you will have to implement some mechanism to manage DynamoDB exceptions when available capacity is under pressure.
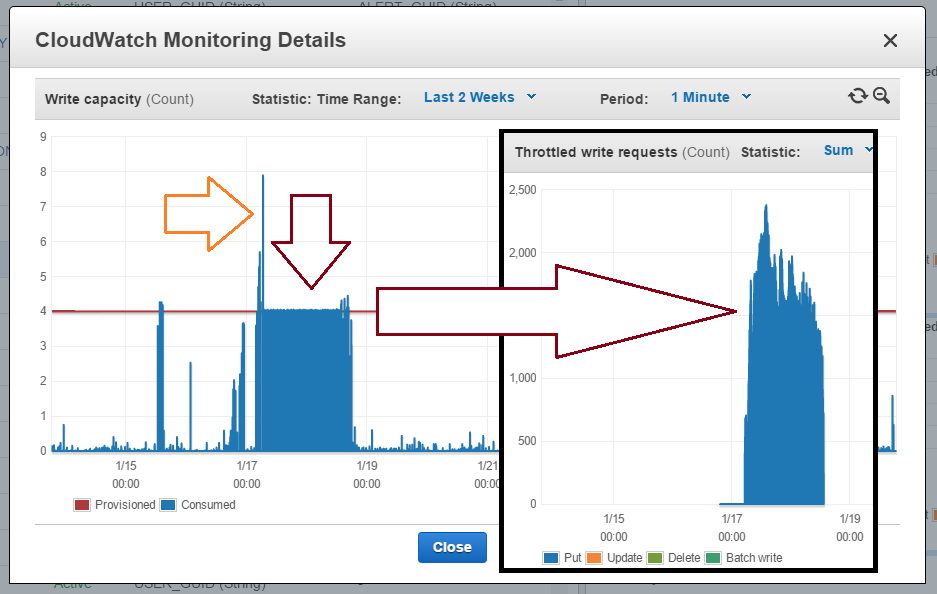
We need to catch write exceptions:
I tried that way pushing data to AWS SQS Queues on Write capacity exceptions, and popping it later to restart the write process to Dynamo table. Depending on your numbers that may be a good strategy, but in my case It becomes a SQS + DynamoDB database instead of just a noSQL (adding a new cost for processing those Millions of GPS location messages every day).
After some time tuning that solution, I decided to move forward and found option 2.
That means no scale strategy, and you will have to implement some mechanism to manage DynamoDB exceptions when available capacity is under pressure.
We need to catch write exceptions:
} catch (ProvisionedThroughputExceededException e) {
ManageDynamoDBCapacityException(data);
}
I tried that way pushing data to AWS SQS Queues on Write capacity exceptions, and popping it later to restart the write process to Dynamo table. Depending on your numbers that may be a good strategy, but in my case It becomes a SQS + DynamoDB database instead of just a noSQL (adding a new cost for processing those Millions of GPS location messages every day).
After some time tuning that solution, I decided to move forward and found option 2.
Option 2: Dynamic DynamoDB
There is an excellent solution for auto-scaling named Dynamic DynamoDB. Take a look at the link from AWS Official Blog or visit the documentation from the author. Basically it's a job that ask DynamoDB Metrics about your table, and scales capacity based on the results. Something like "are you ok? yes. are you ok? yes. are you ok? No. Ok, scale capacity. Are you ok?.. etc" .
My only concerns on that solution are 1) you will need to set high frequency for table checks if you want to prevent capacity issues asap, 2) fetching table metrics has a cost (Dynamic DynamoDB use ConsumedReadCapacityUnits, ReadThrottleEvents, ConsumedWriteCapacityUnits and WriteThrottleEvents metrics) so do not set a high fetching frequency or you will pay for it.

Be careful on the frequency you set for Dynamic DynamoDB config ;).
Dynamic DynamoDB works well when your table throughput requirements change 'slowly' (you write 10, then 20, then 30, ..), but for fast-coming peaks (write 10, then write 1000) it's less convenient. So I moved for option 3 ;).
There is an excellent solution for auto-scaling named Dynamic DynamoDB. Take a look at the link from AWS Official Blog or visit the documentation from the author. Basically it's a job that ask DynamoDB Metrics about your table, and scales capacity based on the results. Something like "are you ok? yes. are you ok? yes. are you ok? No. Ok, scale capacity. Are you ok?.. etc" .
My only concerns on that solution are 1) you will need to set high frequency for table checks if you want to prevent capacity issues asap, 2) fetching table metrics has a cost (Dynamic DynamoDB use ConsumedReadCapacityUnits, ReadThrottleEvents, ConsumedWriteCapacityUnits and WriteThrottleEvents metrics) so do not set a high fetching frequency or you will pay for it.
Be careful on the frequency you set for Dynamic DynamoDB config ;).
Dynamic DynamoDB works well when your table throughput requirements change 'slowly' (you write 10, then 20, then 30, ..), but for fast-coming peaks (write 10, then write 1000) it's less convenient. So I moved for option 3 ;).
Option 3: option 2 + option 1
Dynamic DynamoDB is able to fetch table status and detect when it may be under pressure on the near future. But when your capacity needs change suddenly (people wake up and power on the mobile for example) Dynamic DynamoDB is not able to prevent this.
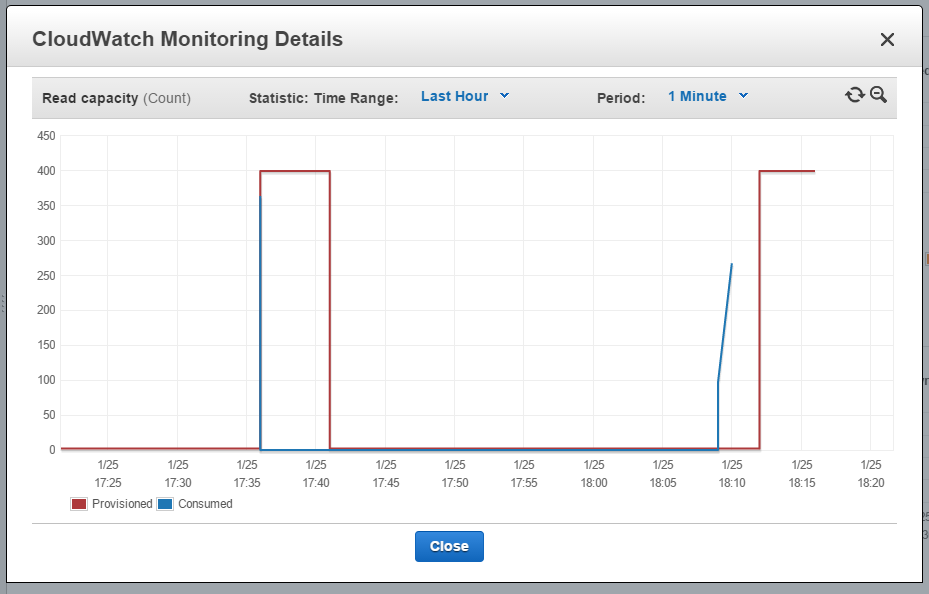
Also note that scaling capacity is not an instant operation, and the time AWS takes to scale is unpredictable (check the picture: in both peaks, scaling up were triggered at the same time, but the 2nd UpdateTableRequest takes longer -).
Finally then:
Considering all this I finally setup my option-3 auto scaling strategy as this:
Dynamic DynamoDB is able to fetch table status and detect when it may be under pressure on the near future. But when your capacity needs change suddenly (people wake up and power on the mobile for example) Dynamic DynamoDB is not able to prevent this.
Also note that scaling capacity is not an instant operation, and the time AWS takes to scale is unpredictable (check the picture: in both peaks, scaling up were triggered at the same time, but the 2nd UpdateTableRequest takes longer -).
Finally then:
- You always need to set a catch exception strategy when using DynamoDB.
- As DynamoDB tables will not always going to be available, you will need to push data somewhere while recovering.
- When Provisioned Throughput Exception occurs, you must scale your capacity. That new capacity can take some minutes to be available.
- You can check some time later if provisioned capacity is needed anymore to save some money.
Considering all this I finally setup my option-3 auto scaling strategy as this:
- Use Dynamic DynamoDB with low fetching frequency Use AWS Lambda routines to manage
DynamoDB scaling.
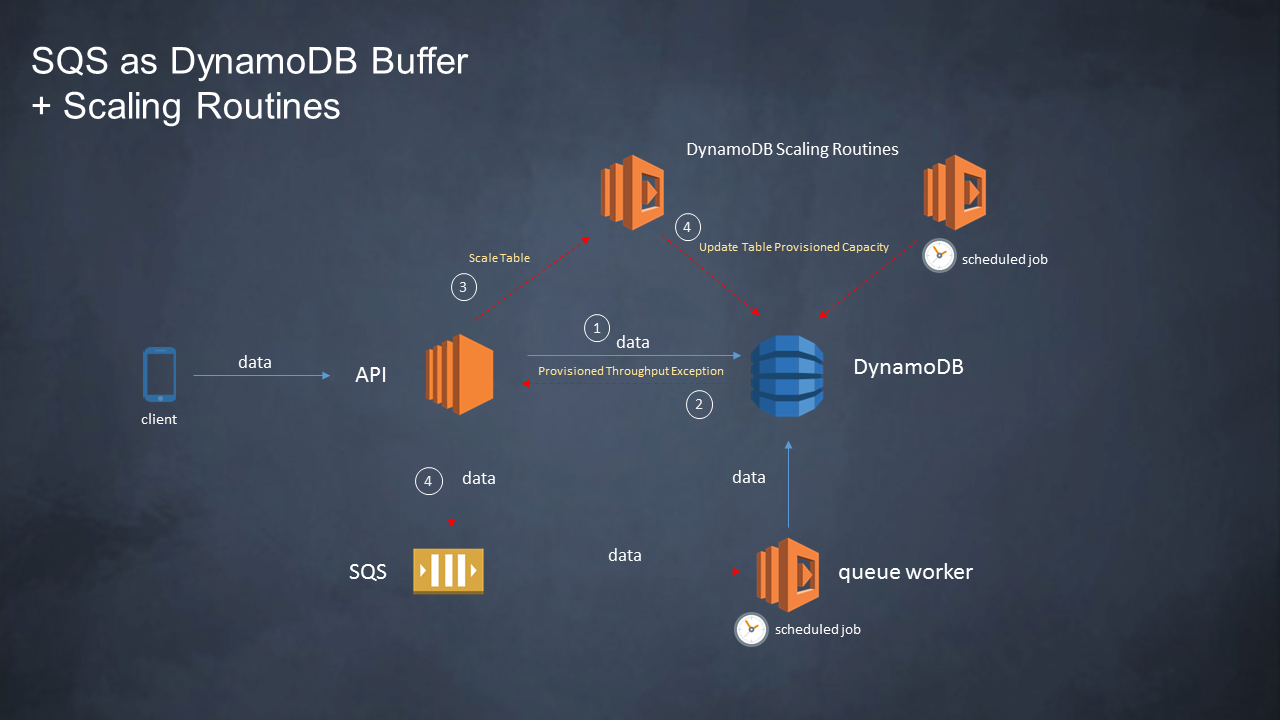
This will prevent some througput demands but also scale down capacity when possible (domage you can only decrease capacity 4 times a day). - Catch capacity exceptions (only on writes*) and use SQS as DynamoDB Buffer (Check for AWS RE:Invent 2013 slide):
- Scale related table capacity.
- Send data to SQS while table is on capacity stress.
- Wait for capacity availability and send data from SQS again.
To get some implementation notes go part II.
Some other interesting options.
- Using AWS Lambda Scheduled tasks to Scale Dynamodb
Great if your capacity needs are predictable (ex. from 6 to 9, scale up).